本文介绍下载python下载网络图片的方法,包括通过图片url直接下载、通过re/beautifulSoup解析html下载以及对动态网页的处理等。
通过pic_url单个/批量下载
已知图片url,例如http://xyz.com/series-*(1,2..N).jpg,共N张图片,其链接形式较为固定,这样经简单循环,直接通过`f.write(requests.get(url).content)’即可以二进制形式将图片写入。
import os
import requests
def download(file_path, picture_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE",
}
r = requests.get(picture_url, headers=headers)
with open(file_path, 'wb') as f:
f.write(r.content)
def main():
os.makedirs('./pic/', exist_ok=True) # 输出目录
prefix_url = 'http://xyz.com/series-' # 同一类目下的图片url前缀
n = 6 # 该类目下的图片总数
tmp = prefix_url.split('/')[-1]
for i in range(1, n + 1):
file_path = './pic/' + tmp + str(i) + '.jpg'
picture_url = prefix_url + str(i) + '.jpg'
download(file_path, picture_url)
if __name__ == '__main__':
main()
正则re解析html获取pic_url后下载
在实际操作中,图片url按序排列情况较少,多数情况下用户仅知道网页url,需要对当前网页htnl内容进行解析,获取源码中包含的图片url,常用方法有正则表达式匹配或BeautifulSoup等库解析的方法。
正则re解析的思路是:首先通过requests.get(url).text获得当前页面html源码;然后通过正则表达式匹配图片url,如re.compile(r'[a-zA-z]+://[^\s]*\.jpg') 正则式一般会得到.jpg结尾的url,但其他网站图片url可能会以.png或.webp等结尾,甚至需要其他的正则匹配,为此,读者需要对正则表达式有所了解,强烈推荐正则表达式30分钟入门教程;将前一步得到的图片url加入列表,进行下载。
import os
import re
import requests
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36 ",
}
html = requests.get(url, headers=headers).text
return html
def parse_html(html_text):
picre = re.compile(r'[a-zA-z]+://[^\s]*\.jpg') # 本正则式得到.jpg结尾的url
pic_list = re.findall(picre, html_text)
return pic_list
def download(file_path, pic_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36 ",
}
r = requests.get(pic_url, headers=headers)
with open(file_path, 'wb') as f:
f.write(r.content)
def main():
# 使用时修改url即可
url = 'http://xyz.com/series'
html_text = get_html(url)
pic_list = parse_html(html_text)
os.makedirs('./pic/', exist_ok=True) # 输出目录
for pic_url in pic_list:
file_name = pic_url.split('/')[-1]
file_path = './pic/' + file_name
download(file_path, pic_url)
if __name__ == '__main__':
main()
通过bs4获取pic_url
与正则匹配思路类似,只不过通过Beautiful Soup解析html获得图片url列表,然后依次下载图片。由于各网站html结构有差异,用户需要自行进行适当修改。以下代码是对豆瓣图片的下载。
import os
import time
import requests
from bs4 import BeautifulSoup
def get_html(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
html = requests.get(url, headers=headers).text
return html
def parse_html(html_text):
soup = BeautifulSoup(html_text, 'html.parser')
li = soup.find_all('div', attrs={'class':'cover'})
pic_list = []
for link in li:
pic_url = link.find('img').get('src')
pic_url = pic_url.replace('/m/', '/l/')
pic_list.append(pic_url)
return pic_list
def download(file_path, pic_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36 ",
}
r = requests.get(pic_url, headers=headers)
with open(file_path, 'wb') as f:
f.write(r.content)
def main():
'从豆瓣下载石原里美图片,观察发现每页包含30张图片,其url按30递增,如下所示'
pic_list = []
for i in range(10):
url = 'https://movie.douban.com/celebrity/1016930/photos/?type=C&start=' + str(30*i) + '&sortby=like&size=a&subtype=a'
html_text = get_html(url)
pic_list += parse_html(html_text)
os.makedirs('./pic/', exist_ok=True) # 输出目录
for i, pic_url in enumerate(pic_list):
if i%30 == 0:
print('正在下载第%s页'%(i/30+1))
file_name = pic_url.split('/')[-1].split('.')[0] + '.jpg'
file_path = './pic/' + file_name
download(file_path, pic_url)
if __name__ == '__main__':
main()
在下载图片时,发现可以直接访问图片的缩略图url进行下载,但由于豆瓣的反爬策略,直接访问原图url会被服务器拒绝,见下图。解决方法见下一部分。
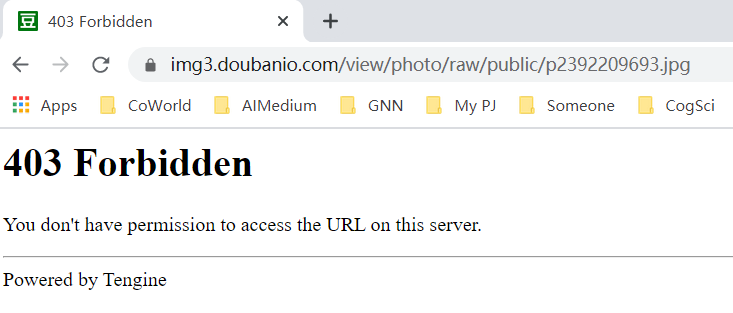
可能遇到的问题
-
网站反爬虫机制
- User-Agent:模拟浏览器访问,添加后,服务器会认为是浏览器正常的请求。一般与网页操作相关访问都予以添加。
- Referer:浏览器以此来判断你从哪一个网页跳转过来。例如在上述豆瓣图片的下载示例中,直接输入网址会被拒绝,但你在网站一步步点击却会在同一地址中得到内容,这就是因为你在一步步访问时是有一个前序跳转地址的,这个地址可以通过“F12”在header中得到,如果找不到的话试一试根目录地址“https://movie.douban.com/”,或是前几步的地址”https://movie.douban.com/celebrity/1016930“,有时referer并不是那么严格。具体实现代码可见我的GitHub仓库’adv_bs4_url.py‘文件。
- ip伪装:构建ip池。
- Cookie伪装:cookie是服务器用来辨别你此时的状态的,每一次向服务器请求cookie都会随之更新。
-
常用正则式匹配
- 强烈推荐正则表达式30分钟入门教程
-
网页的数据采用异步加载,如js渲染的页面或ajax加载的数据通过get不到完整页面源码。
-
一种方案是常说的动态爬虫,即采用一些第三方的工具,模拟浏览器的行为加载数据,如Selenium、PhantomJs等。网络上有较多介绍文章,有点麻烦就没有自己写了,后续有需求的话在做吧,不过其他方法已经够用了。
-
另外可以通过分析页面,找到请求借口,加载页面。其核心就是跟踪页面的交互行为 JS 触发调度,分析出有价值、有意义的核心调用(一般都是通过 JS 发起一个 HTTP 请求),然后我们使用 Python 直接访问逆向到的链接获取价值数据。通过”F12”进行分析,例如对于花瓣网,可以获得其链接为”https://huaban.com/search/?q=%E7%9F%B3%E5%8E%9F%E9%87%8C%E7%BE%8E&kbk95lmw&page=4&per_page=20&wfl=1”,如下图所示,更改“page=*”得到其他页面,
request.urlopen(url).read()读取网页。
-
-
其他问题…
Pyautogui,鼠标模拟点击的“傻瓜式”流程
本方法仅适用于重复性的工作,而且效率较低,但完全没有被反爬虫策略屏蔽的风险。其核心思想与word中的“宏”类似,就是你告诉计算机一次循环中鼠标分别如何操作,然后让其自动循环。代码简单明了。
import pyautogui
import time
pyautogui.FAILSAFE = True
def get_mouse_positon():
time.sleep(3) # 此间将鼠标移动到初始位置
x1, y1 = pyautogui.position()
print(x1, y1)
pyautogui.click(x=x1, y=y1, button='right') # 模拟鼠标右键点击,呼出菜单
time.sleep(5) # 此间将鼠标移动到“save image as...”选项中央
x2, y2 = pyautogui.position()
print(x2, y2)
pyautogui.click(x=x2, y=y2) # 模拟鼠标左键点击,点中“save image as...”
time.sleep(10) # 此间弹出保存文件弹窗,自行选择保存位置,并将鼠标移至“保存(S)”按钮中央
x3, y3 = pyautogui.position()
pyautogui.click(x=x3, y=y3)
print(x3, y3)
def click_download(N):
for i in range(N): # 拟下载图片数量
pyautogui.click(x=517, y=557, duration=0.25, button='right') # 呼出菜单,自行将x/y设置为x1/y1
time.sleep(1)
pyautogui.click(x=664, y=773, duration=0.25) # 下载,x/y为x2/y2
time.sleep(1)
pyautogui.click(x=745, y=559, duration=0.25) # 保存,x/y为x3/y3
time.sleep(1)
pyautogui.click(x=517, y=557, duration=0.25) # 进入下一张图片
time.sleep(2) # 取决于网络加载速度,自行设置
if __name__ == "__main__":
# get_mouse_positon() # 一开始只运行此命令,获取屏幕坐标,后续注释掉该句
click_download(10)
